



























How Client-Side and Server-Side Tracking Actually Work
Tracking on Shopify depends on two different systems: client-side and server-side. While they can send the same types of events, they operate in very different ways.
Tracking Methods Comparison
| Client-Side Tracking | Server-Side Tracking | Hybrid Setup | |
|---|---|---|---|
| Tracking Location | Browser (front-end) | Backend / APIs | Both |
| Setup Complexity | ✅ Easy | 🛠️ Requires technical knowledge or 3rd party app | ❗ More complex but complete |
| UTM & Session Data | ✅ Captures UTMs, referrals | ❌ Limited | ✅ Available via client-side |
| Purchase Events | ❌ May fail | ✅ Tracked | ✅ Captured & no double counts |
| Behavior Events | ✅ Tracks user actions | ❌ Limited coverage | ✅ Captured via client side |
| GDPR Compliance | ✅ Handled via browser scripts | ⚠️ Needs proper consent relay | ✅ Fully compliant |
| Event Match Quality (EMQ) | ❌ Lower due to missing identifiers | ✅ Stronger via hashed data | ✅ Best match rate using both layers |
| Browser & Ad Blocker Restrictions | ❌ Vulnerable | 🆗 Minimal impact | ✅ Strong coverage |
1. What Is Client-Side Tracking?
![]()
Client-side tracking runs in the visitor’s browser. This is the standard method used by pixels and tags — such as GA4, Meta Pixel, and TikTok Pixel — to track user activity.
For example, when a user reaches the “thank_you” page, the Meta Pixel fires a purchase event using data available in the browser.
Google Tag Manager (web container) also uses browser-based triggers and cookies to send events like add_to_cart or begin_checkout to GA4.
This method depends on the browser environment working properly — which isn’t always the case.
![]()
Tracking can break if:
The visitor uses an ad blocker or private browsing mode
Safari or iOS blocks third-party cookies or scripts
The user closes the page before the tracking script fires
When that happens, you lose valuable data without knowing it.
2. What Is Server-Side Tracking?
![]()
Server-side tracking runs independently of the browser. Instead of firing scripts from the front-end, Shopify’s backend sends the event data directly to platforms like GA4, Meta, or TikTok using APIs.
For instance, when an order is completed, Shopify can trigger a webhook and send a purchase event to Meta’s Conversions API (CAPI) — even if the pixel was blocked.
GA4’s Measurement Protocol and TikTok’s Events API allow the same type of server-to-platform delivery.
![]()
Because it doesn’t rely on browser conditions, this method is more stable.
Even if cookies are disabled or the user leaves the page early, the event still gets sent from the backend.
Shopify’s first-party data — like order ID, customer email hash, and product IDs — can be used to match conversions more accurately across platforms.
This makes server-side tracking especially valuable for key events like purchases.
3. Comparing the Two Approaches
Each tracking method plays a different role, and understanding their strengths helps clarify why both are still used.
| Aspect | Client-Side Tracking | Server-Side Tracking |
|---|---|---|
| Where it runs | In the browser | In the backend (e.g., Shopify server) |
| What it depends on | Scripts, cookies, and page loads | API calls, webhook data, backend logic |
| Risk of data loss | High: ad blockers, consent issues, iOS | Low: independent from browser behaviors |
| Best for | Session behavior, UTMs, user actions | Conversions, purchases, post-checkout events |
Client-side tracking is necessary to capture session behavior and traffic sources — like where a user came from and what products they viewed.
Server-side tracking ensures that key events like purchases are delivered accurately — even when the browser fails to cooperate.
What Server-Side Tracking Can’t (and Can) Really Do
Server-side tracking is often misunderstood — especially when merchants assume it will solve all their data problems or somehow bypass compliance obligations.
![]()
❌ Misconception #1: “Server-side tracking replaces client-side tracking.”
This is the most widespread — and most dangerous — misconception.
Even if your server-side setup is perfectly built, it cannot collect:
UTM parameters and traffic source data
Consent signals
Client identifiers like fbp, ttclid, or client_id
These are all set and stored by browser scripts. Without the client layer, you lose visibility into how users arrived, what they did, and whether they gave permission to be tracked.
✅ That’s why platforms like GA4, Meta, and TikTok explicitly recommend using both layers — and deduplicating events using event_id to prevent double counting.
❌ Misconception #2: “Server-side tracking works without user consent.”
Technically, the backend can send data — but legally, that data may be non-compliant if you haven’t captured and honored consent.
Meta, TikTok, and other platforms require that server-side events only be sent if consent is granted.
GA4 allows limited data transmission under Google Consent Mode — but even then, certain marketing features are disabled.
✅ Server-side setups must receive the consent state from the client-side layer, usually passed using Shopify’s Customer Privacy API.
❌ Misconception #3: “Server-side tracking solves all tracking problems.”
It’s true that server-side tracking improves reliability — but it doesn’t cover everything.
It doesn’t capture scrolls, clicks, time on page, or other behavioral events.
It can’t detect how a user navigated through your store.
It won’t know if a user came from a specific campaign unless that data is passed from the browser.
✅ Server-side tracking strengthens purchase reliability, especially during Shopify’s checkout limitations — but it can’t replace behavioral visibility.
❌ Misconception #4: “Server-side tracking lets you avoid GDPR.”
This is a serious misunderstanding. Just because data is transmitted server-to-server doesn’t make it exempt from privacy laws.
The GDPR doesn’t care how the data is collected — only that consent is properly handled and user rights are respected.
Shopify merchants must implement a full consent mechanism, regardless of tracking method.
✅ Server-side tracking still processes personal data (like hashed email or IP), so a compliant setup must include consent banners and proper opt-in logic.
❌ Misconception #5: “You should send everything through server-side.”
Server-side is not always better. In fact, sending all events through the backend may hurt your tracking if:
You lose context from the user session
You fail to pass browser identifiers properly
You try to track behavior events (like view_item, add_to_cart) that are better suited to the browser
✅ The best-performing setups rely on hybrid tracking, where both client-side and server-side methods work together in a coordinated structure. Behavioral and session-based events — such as product views and add-to-cart actions — are captured in the browser, while conversion events like purchase are sent both client-side and server-side with deduplication in place.
This ensures high reliability without sacrificing visibility into the user journey.
Analyzify follows this model by combining browser-based data, backend delivery, and platform-specific consent handling — all aligned with Shopify’s architecture.
Why You Still Need Client-Side Tracking (Hybrid Setup Explained)
![]()
Server-side tracking is powerful, especially for securing critical conversions. But it’s not designed to replace client-side tracking — and using both is essential for a complete, reliable setup on Shopify.
What Client-Side Tracking Still Handles Best
While server-side tracking improves purchase accuracy, it cannot replace what happens inside the browser. Platforms like GA4, Meta, and TikTok still depend on client-side tracking for understanding user behavior.
Client-side tracking is still essential for:
✅ Campaign Attribution: Only browser scripts can capture UTM parameters, referral sources, and session data accurately.
✅ Consent Management: Tools like Shopify’s Customer Privacy API and Google Consent Mode run in the browser. Server-side tracking can only act on the consent already captured by these scripts.
It also covers:
User interactions such as page views, add-to-cart, and product clicks
Scroll depth, session timing, and customer journeys before checkout
Real-time campaign performance and behavioral reports in ad platforms
Without these, your reports become “invisible” in key moments of the customer journey.
The Power of the Hybrid Setup
That’s why Meta, TikTok, and GA4 all recommend hybrid tracking: firing the same events both through the browser (Pixel) and via server (CAPI, Events API, GA4 Measurement Protocol).
Using both ensures:
Event Reliability: If one method fails (e.g., due to ad blockers or browser issues), the other still delivers the data.
Event Deduplication: When configured correctly, both events are matched using a unique event_id, so the platform counts it only once — avoiding double counting and ensuring attribution accuracy.
For example, Analyzify automatically handles this by syncing Pixel and CAPI/Events API with deduplication in place — meaning your purchase data is tracked once, cleanly, and accurately across platforms.
What Happens If You Only Use One Side?
Many merchants assume one method is enough — but relying solely on either client-side or server-side tracking creates serious gaps in your data.

If you rely only on client-side tracking:
❌ You’ll lose conversion data due to ad blockers, Safari restrictions, or thank-you page skips.
❌ Events might never fire if the browser script is blocked — leading to gaps in GA4, Meta, and TikTok reports.
If you rely only on server-side tracking:
❌ You’ll miss session-level signals, UTMs, referral sources, and consent status.
❌ No way to track non-conversion actions like scrolls, views, and in-page clicks — all of which feed ad platforms’ optimization.
In short: neither side is sufficient alone. But together, they cover the full journey — from product view to purchase, and from campaign click to conversion.
Understanding Shopify’s Tracking Structure
When it comes to tracking, Shopify introduces structural challenges that merchants need to understand. These limitations affect both client-side and server-side setups and require special implementation strategies.
Why Checkout and Platform Design Break Standard Tracking
Shopify’s checkout system — especially under Checkout Extensibility — runs in a sandboxed environment. This means that you can’t freely execute tracking code during the checkout process, even if you use tools like Google Tag Manager.
![]()
For example, scripts that would normally fire on payment step or order confirmation may simply not run if they’re injected through conventional means.
Only approved tracking via Shopify’s Customer Events system is allowed in this area — and it doesn’t offer full flexibility or granularity.
External payment gateways like PayPal or Klarna also introduce data loss. When users complete payment outside Shopify and don’t return to the thank_you page, client-side tracking fails silently.
- These gaps cause underreported conversions and broken attribution across platforms like Meta and GA4.
In short: even if your campaigns perform well, Shopify’s architecture may block your ability to prove it.
What Server-Side Tracking Solves — and What It Still Needs
Server-side tracking isn’t blocked by browser limitations — but it still depends heavily on Shopify-specific logic and accurate consent handling to be effective.
![]()
What it solves:
Tracks purchases reliably via webhooks or backend APIs — even when the browser fails.
Recovers conversions missed by client-side tracking (e.g., PayPal flows, subscription renewals).
Sends first-party data (like hashed email, phone, and order ID) for stronger event matching.
But server-side tracking is not fully independent.
It still relies on client-side tools to capture and pass consent signals. Under GDPR and similar laws:
If consent is not granted (or not properly captured), server-side tracking must remain limited or inactive.
Platforms like Google Consent Mode and Shopify’s Customer Privacy API are essential to sync consent preferences between browser and server.
For Shopify-specific tracking, additional logic is required:
Wait for order_status = paid, not just order_created, to avoid false positives.
Handle Draft Orders, which bypass the normal checkout steps.
Support non-standard flows like app-triggered subscriptions or delayed payment links.
Native Integrations Aren’t Enough — Even for Advanced Tools
Shopify’s built-in Facebook, Google, and TikTok Sales Channels offer limited control over tracking. These apps may inject overlapping pixels or server-side events — which can conflict with custom setups or create duplicate events.
Merchants often disable “automatic data sharing” in these sales channels to avoid conflicts.
These built-in tools lack visibility, debugging options, and customization — especially for advanced campaigns.
Even tools like Analyzify, which offer reliable tracking solutions, must still navigate Shopify’s platform limitations.
No tool can bypass the fundamental constraints imposed by the platform — such as restricted checkout access or rigid consent flows.
That’s why accurate tracking on Shopify doesn’t come from just installing an app. It requires a system that respects Shopify’s architecture while covering its blind spots — through both browser and backend layers.
How Server-Side Tracking Boosts Accuracy & Attribution
Client-side tracking on Shopify typically captures only 75–85% of conversions — and that’s in ideal conditions. Server-side tracking significantly increases this accuracy, often reaching 95–98%, especially for critical events like purchases.
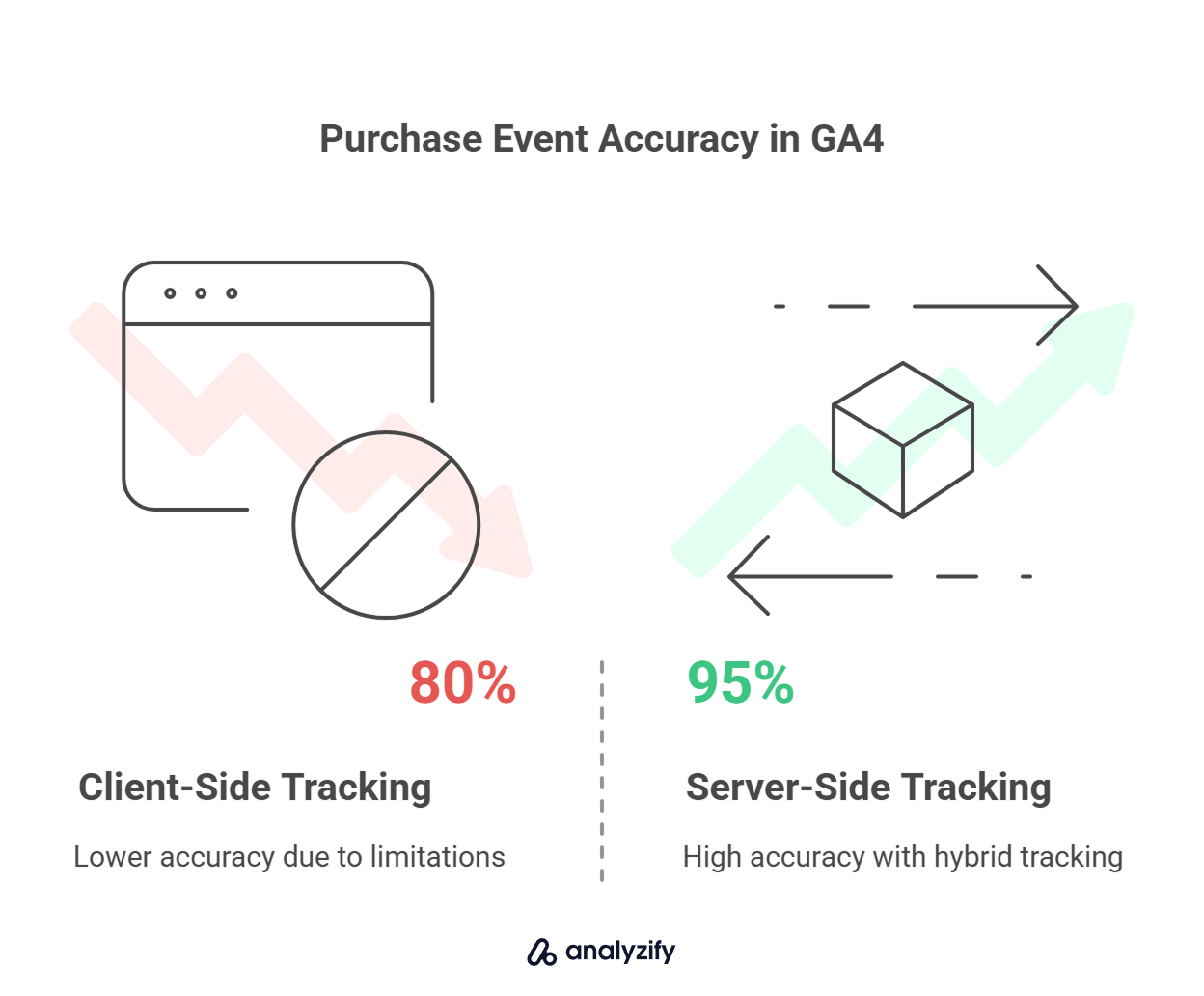
But this improvement doesn’t come from just “sending events via the server” — it happens when the tracking setup is tailored for Shopify’s architecture and includes platform-specific logic.
Where Client-Side Accuracy Breaks Down
Browser-based tracking is highly sensitive to disruptions. Even if your tags are correctly placed:
Ad blockers and iOS privacy policies can silently block pixel requests.
Safari often prevents third-party cookies from persisting across sessions.
Customers using PayPal, Klarna, or other gateways may never return to the thank_you page — the point where most client-side purchases are tracked.
Even minor issues like page load delays or consent not being accepted can cause your entire purchase event to fail.
✅ That’s why relying solely on browser-side data typically results in underreported revenue, broken attribution, and skewed ROAS metrics.
What Server-Side Tracking Recovers (And How)
Server-side tracking fills in the gaps left by client-side methods — especially for purchase events that are lost due to browser failures, ad blockers, and Shopify’s thank_you page limitations.
When correctly implemented, it allows you to track critical conversions directly from Shopify’s backend — even if the front-end scripts fail or never run.
![]()
For example, if a customer completes their purchase using PayPal and doesn’t return to the thank_you page, client-side tags will fail. But server-side events still get delivered reliably using Shopify’s webhook infrastructure.
Similarly, if tracking is blocked by iOS privacy settings or browser extensions, server-side delivery can bypass those blocks and capture the event.
These events often include high-confidence user identifiers like hashed email or phone numbers, which dramatically improve match quality on platforms like Meta and TikTok — but only when the user has given consent.
When used in parallel with client-side tracking and configured with proper event_id values, platforms deduplicate events automatically — ensuring that each conversion is counted once, and only once.
✅ In GA4, this setup can increase purchase event accuracy from ~80% to as high as 95–98% — a result we’ve consistently seen when hybrid tracking is implemented correctly.
And beyond the numbers, this improvement creates real impact:
Campaign optimization becomes more effective because platforms receive more complete signals.
ROAS and conversion reports become more trustworthy, especially in performance-heavy platforms like Meta Ads Manager.
Reporting stability improves across devices, browsers, and channels where client-side tracking often fails silently.
Shopify-Specific Accuracy Wins
This level of improvement is possible only with a Shopify-specific setup that accounts for the platform’s unique structure:
Webhooks that fire on order_status = paid (not draft or pending orders)
Currency handling under Shopify Markets
Post-checkout purchase flows and subscription renewals
Proper consent logic passed from Shopify’s Privacy API to the server
Analyzify’s implementation is built around these Shopify-specific conditions — and it’s this alignment that enables consistent, high-accuracy event delivery across platforms.



